How it works
Submit a report. Get the audit.
1
Upload the governing documents; versions and amendments handled.
2
Submit the AI-written report, from any tool.
3
Get the audit — per-claim verdicts, evidence quotes, omissions, human sign-off.
4
Export the proof — a signed evidence packet an examiner can verify offline.
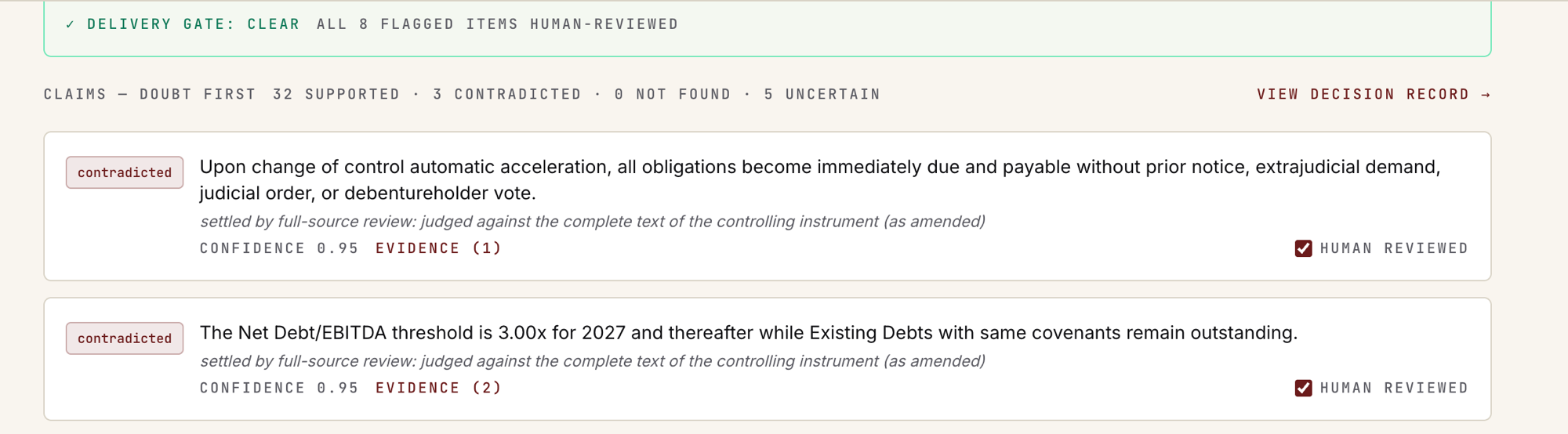
The production console: real verdicts on public deal documents, verified by hand against the deed text. An agent can run the whole loop over MCP. See the live demo →
Q: "Is ASC 605 still the controlling revenue standard?"
Standard RAG ASC 605 governs revenue recognition under US GAAP, covering… × cites stale guidance; misses the 2018 supersession.
PortMem No. ASC 605 was superseded by ASC 606 (ASU 2014-09), effective fiscal years beginning after Dec 15, 2017. ✓ signs the verdict.